こんにちは、Treasure Dataサポートの伊藤です。
今回は、Treasure Dataにおける各種IDについて説明していきます。
- なぜIDについて説明するのか?
- UserのID
- JobのID(Hive/Presto/Partial Delete/Result Export/Bulk Load/Bulk Import/Bulk Export)
- Saved QueryのID
- Workflow関係のID
- CDPのID
- 最後に
なぜIDについて説明するのか?
複数人でTreasure Dataの処理について認識合わせする際に有用なのが各種IDです。 IDの種類とその値がわかれば対象処理を一意に特定することができ、認識の齟齬を防ぐことができます。
同じプロジェクト内での会話はもちろんのこと、Tresaure Dataのサポートへお問い合わせいただく際にもどのIDでどの値かをお伝えいただくと、やりとりがスムーズになります。
UserのID
基本的にメールアドレスがユーザーを特定する識別子になるため、あまり利用するケースは少ないかと思いますが、Treasure DataのユーザーごとにIDが割り振られています。
TDコンソールにて Control Panel --> ADMINISTRATION --> Users と遷移するとユーザー一覧が表示されますが、各ユーザーを選択するとURL内にユーザーIDが出現します。

https://console.treasuredata.com/app/cp/us/<ユーザーID>/de
※ console.treasuredata.com 部分は、お使いいただいているTreasure Dataのリージョン毎に異なるため適宜読み替えてください
JobのID(Hive/Presto/Partial Delete/Result Export/Bulk Load/Bulk Import/Bulk Export)
Jobとは
Treasure Dataのコンポーネントとして、Jobというものがあります。 TDコンソールのJob Activitiesにて確認できるもの、とイメージいただくと良いかと思います。
Jobは処理の単位を表し、処理内容としては下記が挙げられます。
| Jobの種類 | Job Activities上のラベル | 処理内容 |
|---|---|---|
| Hive | Hive | クエリエンジンHiveでSQLを実行したJob |
| Presto | Presto | クエリエンジンPrestoでSQLを実行したJob |
| Partial Delete | Partial Delete | td table:partial_deleteコマンドによって実行されるPrestoのDELETE文のJob |
| Result Export | Result Export | HiveやPrestoによって抽出した結果をエクスポートするためのJob |
| Bulk Load | Data Import | Data Connector(Source, Workflowのtd_load>:オペレータ)によるデータインポートのためのJob |
| Bulk Import | Bulk Import Job | td import:autoコマンドや、Embulkのembulk-output-tdプラグインによるデータ投入のJob |
| Bulk Export | Export | td table:exportコマンドなどによるAWS S3へテーブルをエクスポートするためのJob |
そして、例えばあるクエリが失敗した場合は、Jobがエラーとなり利用者は失敗に気づくことができます。 その際、JobにもIDが割り振られ、その値で一意に対象Jobを特定することができます。
Job IDの確認方法
Job Activitiesの画面では下記にJob IDが記載されています。

また、この画面から各Jobをクリックすると、画面の一番上にJob IDが表示されます。

URLにも下記のようにJob IDが含まれますので、お好みの方法でご確認ください。
https://console.treasuredata.com/app/jobs/<JobのID>/query
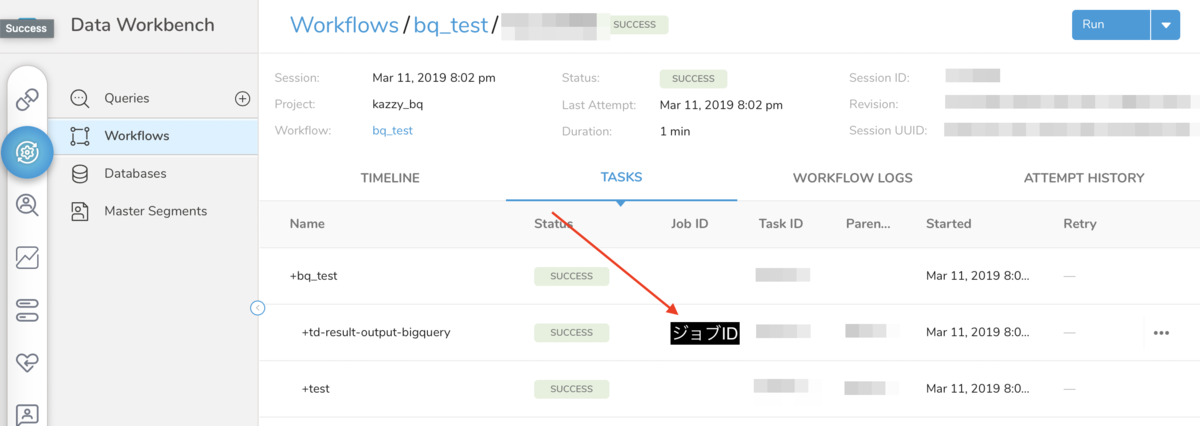
また、WorklflowからJobを実行するということが可能です。 td>: オペレータや td_load>: オペレータを利用すると、Jobが新たに実行されるため、どのJobが実行されたのか確認したい場合はJob IDを知りたいケースがあるのではないかと思います。
TDコンソールにて Data Workbench --> Workflows --> 対象Workflow --> Run Historyタブ --> 対象session --> TASKSタブ と遷移すると表示される画面の Job ID列にWorkflowが実行したJobのIDが表示されます。
Saved QueryのID
Treasure Dataではクエリ文を保存しておき、任意のタイミング及びスケジュール実行させることが可能です。
Data Workbench --> Queries と画面遷移すると保存されたクエリ(Saved Query)の一覧が表示されます。
クエリをクリックするとクエリ文などが表示されますが、その際URLを見てみると下記のようにIDが採番されていることがわかります。
https://console.treasuredata.com/app/queries/editor?queryId=<クエリのID>

実行すると先述したJobが発行されることになるため、1つのSaved QueryとJobの関係は 1対N になります。
「エラーになりました」とお問合せを頂戴した際にSaved QueryのID(URL)を共有いただくことがあるのですが、中身を変更してもSaved QueryのIDは変わらないのでJobのIDを共有したほうが、どういった設定・クエリ文で実行したのかがわかるので調査がしやすいでしょう。
Workflow関係のID
Treasure DataのWorkflowにはコンポーネントが複数あり、それぞれIDが割り振られます。 それぞれの関係性に触れつつIDの確認方法について説明してきます。
Project ID
Projectとは、Workflowで最も上位のコンポーネントとなります。 ディレクトリ・フォルダをイメージしていただくのが良いでしょう。
Projectの中にWorkflow(digファイル)やSQLファイル、Yamlファイルを格納し利用する形になります。
このProjectにもIDは割り振られるのですが、TDコンソールでは確認することができず、取得するにはAPIを利用する必要があります。 下記は curl コマンドでAPIを実行する例になります。
$ curl -X GET -H "AUTHORIZATION: TD1 <API Key>" "https://api-workflow.treasuredata.com/api/projects?name=<Project名>"
上記を実行すると、指定した名前のProjectのIDが下記のようにしてレスポンスとして返り取得することができます(見やすいように整形してあります)。
{
"projects": [
{
"id": "<ProjectのID>",
"name": "<Project名>",
...
Workflow ID
Workflowとは、下記のようなdigファイルを指します。 利用者が実行したい処理内容を記載しているファイルになります。
+task1: echo>: this is 1st task! +task2: echo>: this is 2nd task!
ProjectとWorkflowの関係は 1:Nとなります。
下記のように、1つのProject内に1つ以上のWorkflowが存在するとイメージしてください。
$ tree hogehoge_prj hogehoge_prj <-- Project ├── query_hoge1.sql ├── workflow_hoge1.dig ★これがWorkflow └── workflow_hoge2.dig ★これもWorkflow
TDコンソールでは、 Data Workbench --> Workflows と遷移いただくとWorkflow一覧が表示されます。
Workflowを選択すると、URL内にWorkflowのIDが含まれます。Workflow(digファイル)を編集するとIDが刷新されることもあり、あまり利用することはないかもしれませんね。
https://console.treasuredata.com/app/workflows/<WorkflowのID>/info
Session ID
SessionはWorkflowの実行予定を意味するコンポーネントです。
そのため、WorkflowとSessionの関係は 1:N になります。
実行予定と言われてもイメージしづらいかと思いますので、下記のように日次で実行するスケジュールのWorkflowで説明します。
timezone: Asia/Tokyo schedule: daily>: 07:00:00 +task1: echo>: this is test task!
この場合、下記のように各日付に対応するSessionが存在しそれぞれIDが割り振られます。エラーになった際は、少なくともSessionのIDが情報としてあれば対象処理を特定することができるので、後述する確認方法は覚えておくと良いでしょう。
- 10/27のsession
- 10/28のsession
- 10/29のsession
TDコンソールで確認する場合、 Data Workbench --> Workflows --> 対象Workflow と遷移すると Run History タブにSession一覧が表示され、そこでSessionのIDを確認することができます。
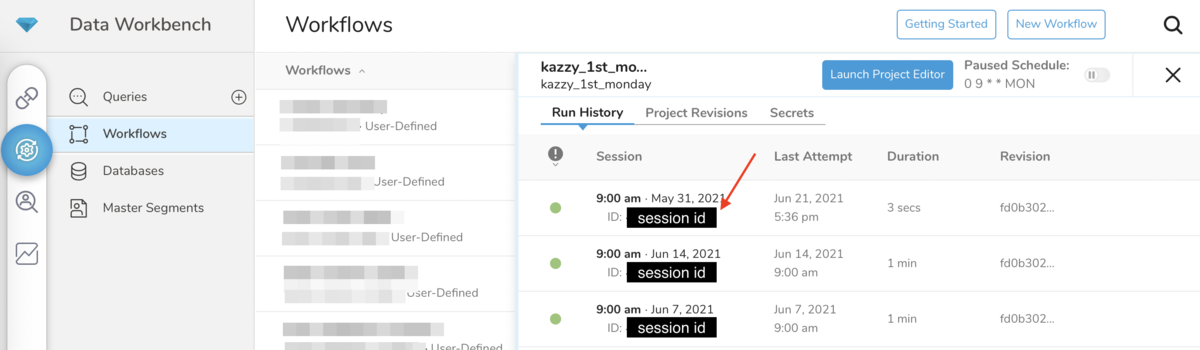
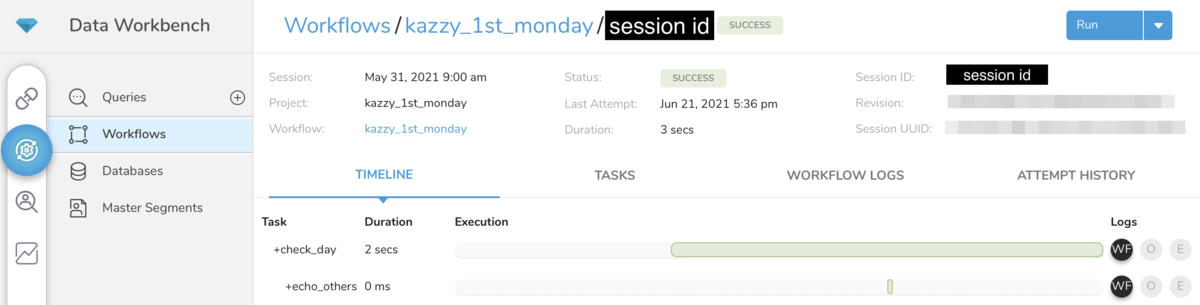
また、Sessionをクリックすると画面上部にSessionのIDが表示されます。
Attempt ID
AttemptはWorkflowの実際の実行を表します。
どの予定に対して実行したかという関係があるため、SessionとAttemptの関係は 1:N 対応になります。
わかりやすい例としては、例えば10/29の実行予定(Session)において、一度エラーになってしまったとします。その後、エラー原因を解消し再実行したところ成功したようなケースを考えます。その場合、下記のように1つのSessionに対して2つのAttemptが紐づきます。
- 10/29のSession
- Attempt(エラー)
- Attempt(成功)
そして、もちろんそれぞれIDが割り振られます。
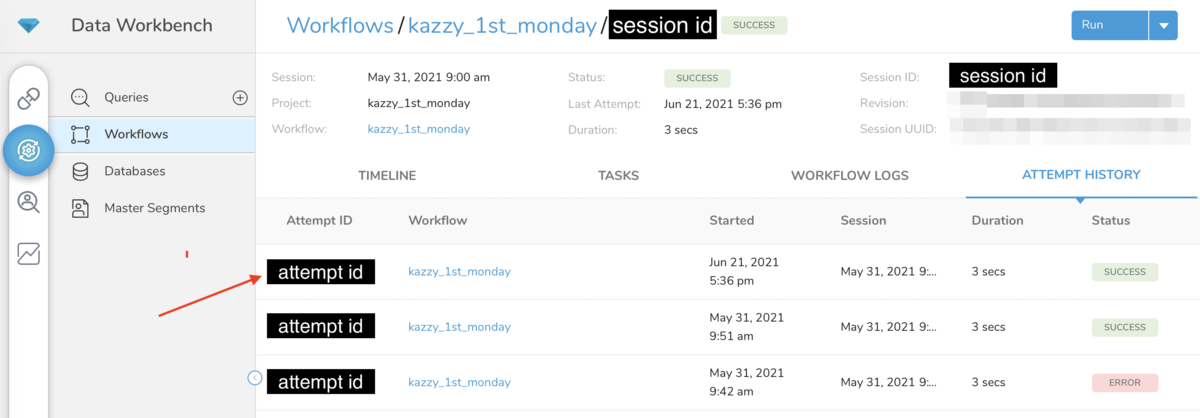
TDコンソールでは Data Workbench --> Workflows --> 対象Workflow --> Run Historyタブから対象Sessionを選択 --> ATTEMPT HISTORYタブ と遷移すると、Attempt ID列にAttemptのIDが表示されるため、こちらで確認可能です。
CDPのID
そもそもTreasure Dataの提供しているサービスがCDPでしょ、とお思いかもしれませんが、エンドポイント一覧に CDP API とある通り、ある機能群のことをCDPと呼びます。
代表的な機能とそのIDの取得方法について説明していきます。
Master Segment(Parent Segment) ID
Master Segmentとは、Treasure Dataのテーブルを元に作成できるマスターデータのことを指します。 格納されているデータの種類によって各テーブルをMaster Table/Behavior Table/Attribute Tableとしてそれぞれ定義し、それらを紐付け(結合)するカラムを指定すると、設定したスケジュールに従って指定されたテーブル達を結合してくれます。
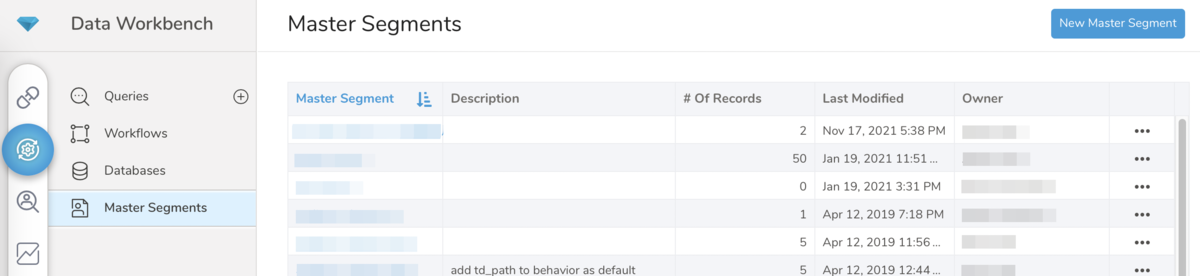
このMaster SegmentもIDが付与されます。TDコンソールで Data Workbench --> Master Segments と遷移すると Master Segment 一覧が表示されます。対象のMaster Segmentをクリックすると下記のようなURLとなり、末尾がMaster SegmentのIDになります。
https://console.treasuredata.com/app/ms/<Master SegmentのID>
Segment ID
Segmentとは、Master Segmentを元に、各種条件でフィルタリングした論理的なデータセットのことを指します。Master Segmentは Master Tableなどインプットとなるデータを元に集計・結合した結果をテーブルとして保持していますが、Segmentはあくまでもフィルタリングするための条件と、その条件によって絞り込まれた・切り出された論理的なデータセットになります。
こちらもIDが付与されます。TDコンソールにて Audience Studio --> Segment & Funnels --> MASTER SEGMENTにて元となるMaster Segmentを選択 と遷移いただくと、選択したMaster SegmentからフィルタリングされたSegment一覧が表示されます。
Segmentをクリックすると下記のようなURLとなり、SegmentのIDを取得することができます。
https://console.treasuredata.com/app/ms/<Master SegmentのID>/se/<FolderのID>/<SegmentのID>/de

Activation ID
Activationとは、Segmentを外部サービス(AWS S3やSFTPサーバーなど)へエクスポートするための機能のことを指します。
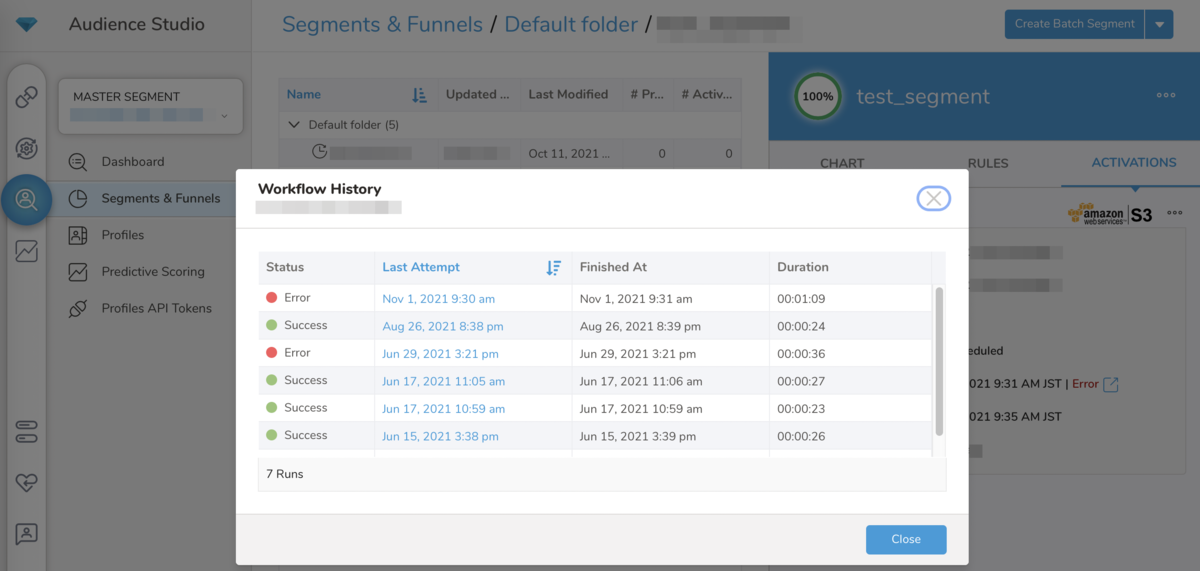
Audience Studio --> Segment & Funnels --> MASTER SEGMENTにて元となるMaster Segmentを選択 --> 対象Segmentを選択 --> ACTIVATIONSタブ と遷移すると、対象Master Segmentから切り出されるSegmentをエクスポートするためのActivation一覧が表示されます。
そこから、対象Activationの右上にある ・・・ をクリックし表示される View History... を選択します。すると、対象Activationの実行履歴が表示されますが、その際のURLは下記のようになっており、
https://console.treasuredata.com/app/ms/<Master SegmentのID>/se/<FolderのID>/<SegmentのID>/ac/<ActivationのID>/wh
最後に
いかがでしたでしょうか?
TDコンソールを利用されている場合であれば、基本的に対象コンポーネントを参照している場合はURLに必要なIDが含まれることがほとんどです。 迷った場合はURLを共有すると、認識の齟齬が防げるかと思いますので、頭の片隅においてもらえると助かります。
また、他のコンポーネントもありますので、それらのID確認方法につきましてはまたどこかのタイミングで記事にしたいと思います。