こんにちは、Treasure Data(TD) サポートの伊藤です。
前回のインポート編に続き、エクスポート編として記事を書こうと思います。 インポートとは異なりエクスポートは機能数が少ないので、とっつきやすく読みやすいと思います。
エクスポートとは
TDにおけるエクスポートとは、その名の通りTDに格納されているデータを外部に出力する機能になります。 よく利用する方法としては下記が挙げられますので、各々細かく見ていきましょう。
- Result Export
- Bulk Export
- クエリの結果のダウンロード
Result Export(Result Output)
TDからデータをエクスポートする際はこの機能を利用することが多いのではないかと思われるメジャーな機能です。エクスポートできるサービスはAWS S3 や MySQL、SFTPサーバーなど多岐にわたります。
機能名の Result とはクエリ(SQL)で抽出した結果のことを指しています。TDでは Hive/Presto という2種類のクエリエンジンを利用することができますが、その何れかを利用して抽出した結果を外部に書き出すことができます。
そのため本機能を利用するには当然ですがクエリを作成・実行する必要があります。
Result Export の使い方
具体的には下記3通りの方法で Result Export 機能を利用することができます。
- TDコンソールからエクスポートする
- Workflowの
td>:オペレーターでエクスポートする - CLI(Toolbelt)の
td queryコマンドでエクスポートする
最後のCLIの場合を除き、事前にエクスポート先の資格情報(接続するユーザー名、ホスト名、パスワード、秘密鍵など)を Authentication として作成しておく必要があります。
もちろん1つの Authentication を複数の Result Export にて利用することができますが、例えば接続するユーザーを変えたいという場合は別途 Authentication を作成して対応することになります。
そして、エクスポート先情報(ファイルパスやテーブル名)やデータのフォーマット情報(区切り文字など)は Result Export ごとに設定します。Authentication と役割が異なるということを意識いただくと設定箇所など混乱しづらいのではないかと思います。
TDコンソールから Result Export を利用する
TDコンソール(Web UI)から Result Export を利用する場合は、クエリ編集画面から設定することになります。
画面右上の Export Results にチェックを入れると Authentication の選択・作成を経て Result Export の設定をすることが可能です。設定完了後 Run をクリックしてクエリを実行すると、クエリによる抽出が完了した後にエクスポート処理が開始されます。

Workflow から Result Export を利用する
Workflowから Result Export 機能を利用するためには td>: オペレーターを使います。 td>: オペレーターはクエリを実行することができるオペレーターですが、result_connection: に Authentication 名を、result_settings: にはエクスポート設定を記載することで実行したクエリの結果をエクスポートすることができます。
例えば S3 へエクスポートする場合は下記のような記載になります。
+td-result-into-s3: td>: queries/sample.sql # クエリ文 result_connection: your_connections_name # Authentication名を記載 result_settings: bucket: your_bucket # S3のバケット名 path: /path/20201127_test.csv # オブジェクトパス(ファイルパス) ...
result_settings: に記載できるオプション名などは連携先サービスによって異なります。そのため、ドキュメントやtreasure-boxesを参照してください。
TDコンソールのクエリから Result Export 機能を利用する場合と比較すると、Workflowでの利用になるため他の処理と依存関係を設けることができるというメリットがあります。また、書き出し先などにWorkflowの変数 ${...} を利用して設定することができるため、例えば下記のように実行予定(sessionと言います)の情報をファイル名に含めるなどの柔軟なユースケースが実現できます。
+td-result-into-s3: td>: queries/sample.sql result_connection: your_connections_name result_settings: bucket: your_bucket path: /path/file_${moment(session_time).format("YYYYMMDD")}.csv.gz # ビルトイン変数 session_time を Moment.js で加工
また、少し Advanced な使い方になりますが、td_result_export>: オペレーターを利用することで Result Export 機能を利用することも可能です。
td>: オペレーターの場合と異なり、過去に成功した Hive/Presto ジョブのIDを指定することで、クエリによる抽出部分をスキップしてエクスポートできます。
あるクエリで抽出した結果を複数の場所にエクスポートしたいときに、何度もクエリを実行する必要がなくなるため有用かと思います。
+export_query_result: td_result_export>: job_id: 12345 result_connection: my_s3_connection result_settings: bucket: your_bucket path: /logs/
CLI(Toolbelt)で Result Export を利用する
CLI(Toolbelt)から Result Export 機能を利用するためには、td query コマンドの --result オプションを指定する必要があります。
td query コマンドのヘルプを見てみましょう。
$ td query --help usage: $ td query [sql] example: $ td query -d example_db -w -r rset1 "select count(*) from table1" $ td query -d example_db -w -r rset1 -q query.txt description: Issue a query options: ... -r, --result RESULT_URL write result to the URL (see also result:create subcommand)
--result <result_url> の <result_url> 部分にエクスポートに必要な情報を URL フォーマットで記載して利用します。エクスポート先によって記載する情報などが異なるため、ドキュメントを参照していただければと思います。
下記はS3にエクスポートする際のサンプルになりますが、URLフォーマットなどを事前に把握しておく必要があるため、TDコンソールやWorkflowから利用するケースが多いかもしれません。 また、エクスポート先の認証情報としてOAuthなどを利用する場合は利用できないため、先述した方法と比べると下火となっている方法かと思います。
$ td query --result 's3://accesskey:secretkey@/bucketname/path/to/file.csv.gz?compression=gz' -w -d testdb "SELECT code, COUNT(1) AS cnt FROM www_access GROUP BY code"
Result Export のジョブについて
Result Export とは Hive/Presto で抽出した結果をエクスポートする機能と説明しましたが、実は Hive/Presto のジョブと Result Export のジョブは別々のジョブとなっています。そのため Job ID も別々の値が割り振られるのですが、Result Export のジョブのログは Hive/Presto のジョブのログに出力されることもあり、TDを利用する上で意識することは少ないのではないかと思います。
クエリ文が RESULT EXPORT FROM JOB <job_id> となっているジョブが Result Export のジョブです。<job_id> はエクスポートするデータを抽出した Hive/Presto のジョブのIDとなっているため、どのジョブの結果をエクスポートしようとしているのかは簡単にわかりますね。

Bulk Export機能
Result Export 機能とは異なり、AWS S3 へのみエクスポートすることができる機能です。
TDのAWSリージョン(ご契約時に決定)とエクスポート先のS3のバケットのリージョンが同一の場合にのみ利用できる機能で、AWSの同一リージョン内での通信となるためネットワークレイテンシーの影響を受けづらく、高速にエクスポートが完了することが期待できるというメリットが挙げられます。
そのためエクスポート先が AWS S3 かつリージョンが同一なのであれば Result Export と本機能のどちらを利用するか検討しても良いかと思います(後述の注意点を考慮して採用するかどうか検討してください)。
具体的には下記いずれかの方法で利用することができます。
- CLI(Toolbelt)の
td table:exportコマンド - Workflowの
td_table_export>:オペレーター
timeカラムの値でエクスポートするデータを絞り込みすることは可能ですが、Result Export とは異なり柔軟にエクスポートするデータを絞り込み・整形することはできない点には注意してください。また、スキーマ設定(カラム名)をヘッダーとして追加するということができません。
エクスポート先ファイルのフォーマットにも注意が必要で、 tsv.gz を利用することをお勧めします。 jsonl.gz というフォーマットも選択可能ではありますが、パフォーマンスが良くないということと後方互換性のために残しているフォーマットになりますので、 tsv.gz をお使いいただくのが良いかと思います。
また、Bulk Export は Hive のリソースを利用します。すでに Hive を多用いただいている場合は本機能とリソースを奪い合ってしまう可能性がありますので、クリティカルな処理と実行時間帯をずらすなどしていただくと良いでしょう。
詳細はドキュメントをご参照ください。
クエリ結果のダウンロード
エクスポートとすると違和感がありますが、手元にクエリにて抽出した結果をエクスポートできると解釈できなくはないかと思いますので紹介させてください。
下記いずれかの方法で実行済みのジョブ(Hive/Presto)の結果をダウンロードすることができます。
- TDコンソールの
Downloadボタン - CLI(Toolbelt)の
td job:show
TDの文字コードは基本的にUTF-8(例えば Result Exports 機能は UTF-8 としてエクスポートします)なのですが、本機能は UTF-8 以外に SJIS としてクエリ結果をダウンロードすることが可能です。
前者利用時に Mode を cli とすることで下記のような具体的なコマンドが表示されますので、コマンド実行などに不慣れな方はそのようにしていただくのも良いでしょう。
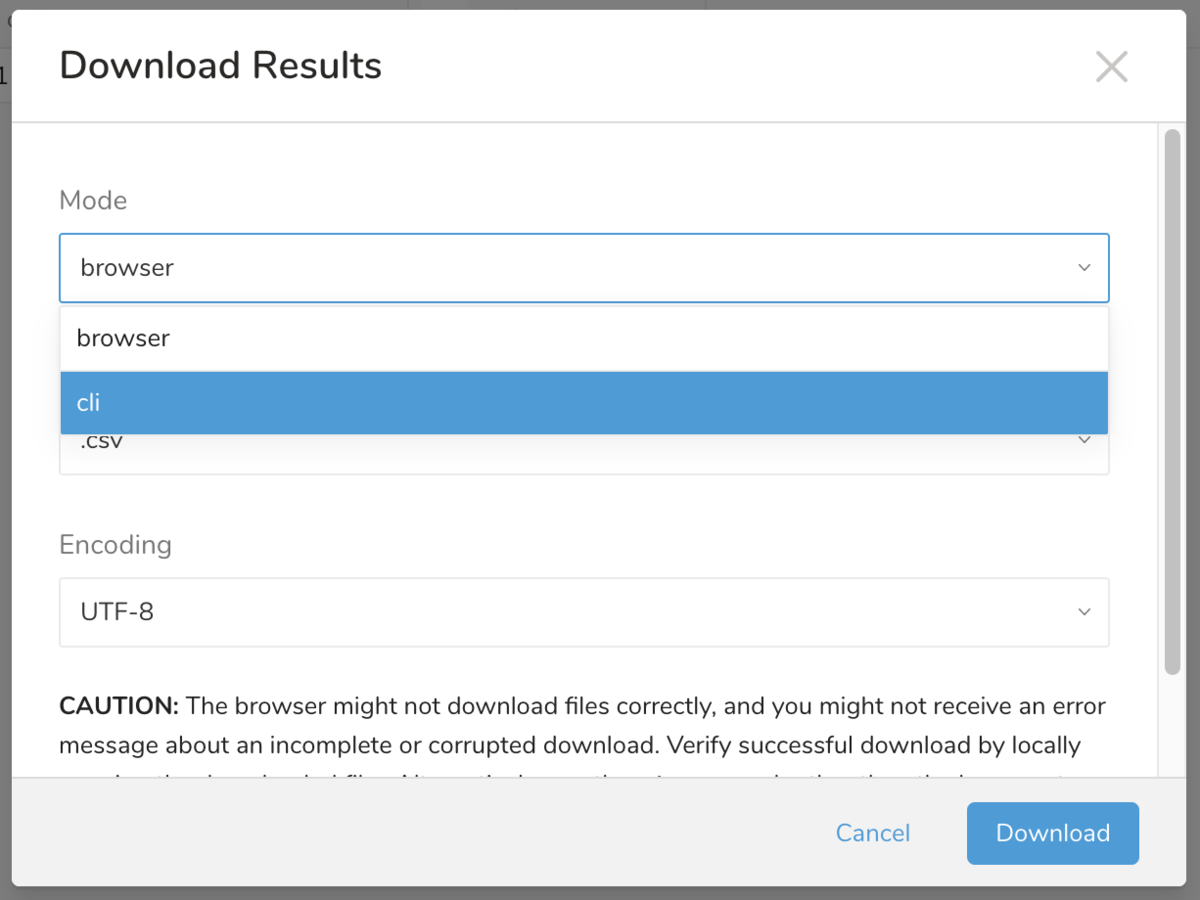
ブラウザ経由でのダウンロードは非常に大きなサイズのファイルをダウンロードしようとしても各種要因で失敗することが多いため、利用できるサイズ上限を設けています。圧縮時のサイズが上限を超えてしまう場合は後者の td job:show コマンドのみ利用できます。
td job:show <job_id> -f csv -o xxxxxxx.csv --column-header
また、 td job:show コマンドでもサイズが大きい場合は長時間化・失敗してしまうことがあります。その場合は迂回策として、S3やSFTPサーバーなどに Result Export 機能でエクスポートし、それを経由してダウンロードするなどでご対応ください。
最後に
TDからのエクスポート機能について簡単にまとめてみましたが、いかがでしたか? インポートに比べて種類が少ないため自身で把握しやすい機能ではあるかと思いますが、理解の一助となりましたら幸いです。