こんにちは。テクニカルサポートチームの大村です。
今回は前回から引き続き、Monitoring Workflow導入後のデータの活用方法について紹介していきます。 前回の記事のステップを踏むことでTDオブジェクト(データベースや認証、ユーザ、ジョブ…)といったメタデータをTDのテーブルに格納されているはずです。 これらのデータを一体どのように使うと便利なのか。というユースケースについて今回はご紹介していきます。
- 1. テーブル一覧
- connections, connections_details, connections_history, connections_details_history
- database, database_history
- schedules, schedules_history
- sources, sources_history
- users, users_history
- policies, policies_history, policies_details, policies_details_history, policies_assign_users, policies_assign_users_history, policies_detail_column, policies_detail_column_history, user_assign_policies, user_assign_policies_history
- 2. クエリサンプル
1. テーブル一覧
まずはMonitoring Workflowにより作成、データが追加されるテーブルを見ていきます。
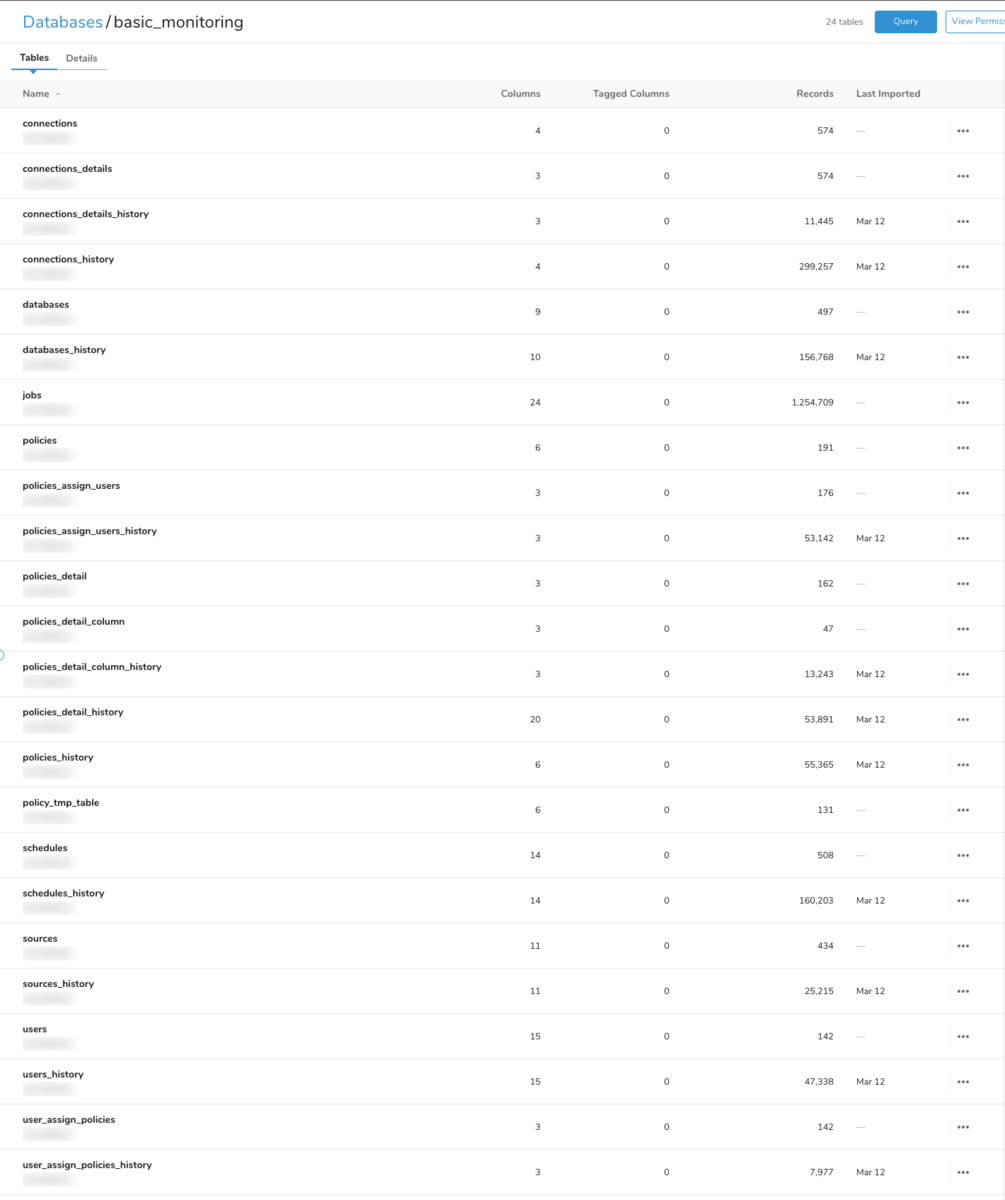
デフォルトでは上記のテーブル群が作成されます。それぞれ、以下のようなデータが格納されています。
connections, connections_details, connections_history, connections_details_history
これらのテーブルにはにAuthenticationオブジェクト関する情報が含まれています。 connectionsにはAuthenticationオブジェクトの名前、設定内容(もちろん、パスワードなどの機密情報は除きます)が保管されています。connection_detailsにはAuthenticationオブジェクトの名前とIDが含まれます。 これらのデータは1日1回その時点のデータにより上書きされます。そのため、過去のデータはxxxx_historyに保管されています。
database, database_history
これらのテーブルにはデータベースに関する情報が含まれます。connectionと同様に1日1回その時点のデータにより上書きされます。そのため、過去のデータはxxxx_historyに保管されます。
schedules, schedules_history
これらのテーブルにはQueryの名前やクエリ内容そのもの、実行スケジュール、指定されているデータベース、所有者名、export設定をしている場合はその内容などが含まれます。 他のテーブルと同じくxxxxには最新のworkflow sessionで取得したデータが含まれ、xxxx_historyには過去のデータが保管されています。
sources, sources_history
これらのテーブルにはSourcesにはID、名前、実行スケジュール、投入先データベース、テーブル、取り込み設定などが格納されています。 他のテーブルと同じくxxxxには最新のworkflow sessionで取得したデータが含まれ、xxxx_historyには過去のデータが保管されています。
users, users_history
これらのテーブルにはUserのIDやfirst_name、last_name、email、作成日などが保管されています。 他のテーブルと同じくxxxxには最新のworkflow sessionで取得したデータが含まれ、xxxx_historyには過去のデータが保管されています。
policies, policies_history, policies_details, policies_details_history, policies_assign_users, policies_assign_users_history, policies_detail_column, policies_detail_column_history, user_assign_policies, user_assign_policies_history
Policy based Permissionの各ポリシー単位(またはユーザ単位)の情報が含まれます。 他のテーブルと同じくxxxxには最新のworkflow sessionで取得したデータが含まれ、xxxx_historyには過去のデータが保管されています。
各テーブルについては以下の通りになります。
| テーブル | 内容 |
|---|---|
| policies | ポリシー名、ID、Description |
| policies_details | ポリシーID、permission(JSONフォーマット) |
| policies_assign_users | ポリシーID、assign_uesrs(JSONフォーマット) |
| policies_detail_column | ポリシーID、column_permissions(JSONフォーマット) |
| user_assign_policies | ユーザID、assign_policy(JSONフォーマット) |
Column Permissionに関しては別テーブルになっていますので、注意すると良いかと思います。
2. クエリサンプル
クエリサンプルおよびその結果イメージの一覧をtreasure-boxes内のREADME.mdにも記載していますので、こちらもあわせて確認すると良いでしょう。 https://github.com/treasure-data/treasure-boxes/tree/master/scenarios/monitoring/basic_monitoring/query_samples
もちろん、これらの結果をcsvファイルでダウンロードしたり、Result Exportの機能を使用して、Google Sheetに出力したりすることも可能です。
| # | ファイル名 | 内容 |
|---|---|---|
| 1 | database_list.sql | データベースIDや名前、作成日、TDコンソールのリンクを含んだデータベース一覧を作成します |
| 2 | connection_list.sql | AuthenticationIDや名前、接続先を含んだ認証情報一覧を作成します |
| 3 | query_list.sql | Queryの名前やエンジンのタイプ、クエリの内容そのもの、所有者、出力先があれば出力先を含んだQuery一覧を作成します |
| 4 | user_list.sql | ユーザIDや名前、email、作成日を含んだユーザ一覧を作成します |
| 5 | db_permission_list_per_policy.sql | ポリシーID、名前、対象データベースに対する操作、対象データベースID、対象データベース名を含んだポリシー一覧を作成します |
| 6 | workflow_permission_list_per_policy.sql | ポリシーID、名前、プロジェクト名、プロジェクトに対する操作を含んだポリシー一覧を作成します |
| 7 | auth_permission_list_per_policy | ポリシーID、名前、Authenticationに対する操作、Authentication ID、名前を含んだポリシー一覧を作成します |
| 8 | parent_segment_permission_list_per_policy.sql | ポリシーID、名前、対象ペアレントセグメントに対する操作、対象ペアレントセグメントID、対象ペアレントセグメント名を含んだポリシー一覧を作成します |
| 9 | num_of_jobs_per_type_and_hours.sql | 1時間毎のジョブタイプ別ジョブ数を作成します |
これらのクエリサンプルを参考にしながら、個々に必要な情報を抽出してみてください。