こんにちは、Treasure Data(以後TD) サポートの伊藤です。
TDは様々な機能を提供しており、利用者ができることが多岐に渡る反面、施策を実現しようとしたときにどういった選択肢があるのか把握しづらい面があるかと思います。 そこで、今さらではありますが今回はTDへインポートする機能について整理してみます。
本記事が皆様の理解の助けになれば幸いです。
- TD機能をグループ分けすると
- インポート機能概要
- 最後に
TD機能をグループ分けすると
TDの機能を大まかに分類すると下記4種類になります。
今回はTDにデータを取り込む、インポート機能について整理していきましょう。
- インポート ★今回対象となっている部分
- エクスポート
- データ処理(Hive、Presto)
- データフロー(Workflow)
インポート機能概要
TDにデータを投入するには下記何れかの方法を利用いただいているかと思います。 それぞれどういった機能を指しているのか見ていきましょう。
| インポートの種類 | 機能名 |
|---|---|
| Streaming Import | JavaScript SDK、Mobile SDK(iOS SDKやAndroid SDK)、Fluentd(td-agent)、Postback API、td table:import |
| Bulk Load | Data Connector、File Upload |
| Bulk Import | Embulk td import:auto、td bulk_import |
| Query | PrestoやHiveによるINESRT文、CREATE TABLE ... AS SELECT文 |
Streaming Import
Streaming Importとは、その名の通り少量のデータを継続的にTDへ送信する際に利用する仕組みです。
送信処理自体が成功していたとしても、実体にそのデータがクエリで抽出できるようになるまではラグが生じる、という特徴があります。
下記が対象機能となりますので、それぞれ見ていきましょう。
- JavaScript SDK(JS SDK)
- Mobile SDK(iOS SDKやAndroid SDKなど)
- Fluentd、td-agent
- Postback API
- td table:importコマンド
JavaScript SDK(JS SDK)
WebサイトにJavaScriptのタグを設置することで、サイト訪問者の情報をトラッキングする際などに利用できる機能です。 デフォルトで各種情報を収集することができますが、ユーザー定義の任意の情報を併せて送信するということも可能です。
Mobile SDK
その名の通り、モバイルアプリケーションのログをTDへ送信するための機能です。 イベント情報をバッファーに蓄積し、任意のタイミングでバッファー内のデータをアップロードするという仕組みになっています。
下記3種類が提供されていますが、先述したJS SDKとは別のSDKとなるため、取得できる情報は異なる点には注意が必要です。
Fluentd(td-agent)
オープンソースのログ収集ツールで、例えばサーバーのログを収集しTDに送信するという使い方が可能です。 Fluentdの安定版をパッケージングした td-agent というツールも提供されており、Fluentdと同じようにして利用することができます。
インプット(データ収集)部分とアウトプット(データ送信)部分でそれぞれプラグインという形で対応できるサービスを拡張することができる部分がよく利点として挙げられます。
また、Fluent bitという類似したツールもありますが、こちらはソフトウェア自体がより軽量となるように開発されており、IoT向けの組み込み機器での利用などが想定されています。
Postback API
1回で1レコードを投入することを想定したAPIです。 利用されるケースとしては 3rd partyベンダー(モバイル向け分析サービスなど)と連携するものや、ピクセルトラッキング(画像を利用したメールの開封状況確認など)が挙げられます。
td table:import コマンド
CLI(Toolbelt)にてインポート処理を実行できる、古くから提供されていたコマンドです。
後述するバルク処理系のコマンドとは異なり、Streaming Importとして実行されますが、新たに利用することはないのではないかと思います。
詳細は私のマネージャーのブログに記載されていますので、よろしければご参照ください。
Streaming Import まとめ
今まで挙げてきた機能は全て Streaming Import と呼ばれる種類のインポート機能になります。
データはTDのサーバーに到達したあとにまとめてテーブルへ反映するという仕組みになっているため、どの機能を使ったとしてもクエリで確認できるまでにラグが発生します。
バッチ処理と比較してやきもきする部分もあるかと思いますが、大量のインポートリクエストを捌くという点では優れており、Webサイトやモバイルアプリケーションなど、クライアント側(みなさまにとってのお客様)の環境で動作させることが可能です。
Bulk Load(Data Connector)
Bulk Load とは、データの投入をバルク処理として実行できる機能のことです。
用語としては一見後述する Bulk Import と同じ機能に見えますが、異なる機能であるため区別する必要があります。
Bulk Load は Data Connector と呼ばれ、具体的には下記から利用することができます。
- Source(TDコンソールから)
- Workflowの
td_load>:オペレータ - CLIの
td conncector:xxxx系のコマンド
本機能を利用することで、各種サービス(AWS S3、SFTPサーバー、Google Cloud Storage、MySQLなど)からTDにデータをインポートすることができます。
Source(Data Transfer)
TDコンソール(Web UI)にて利用することができます。
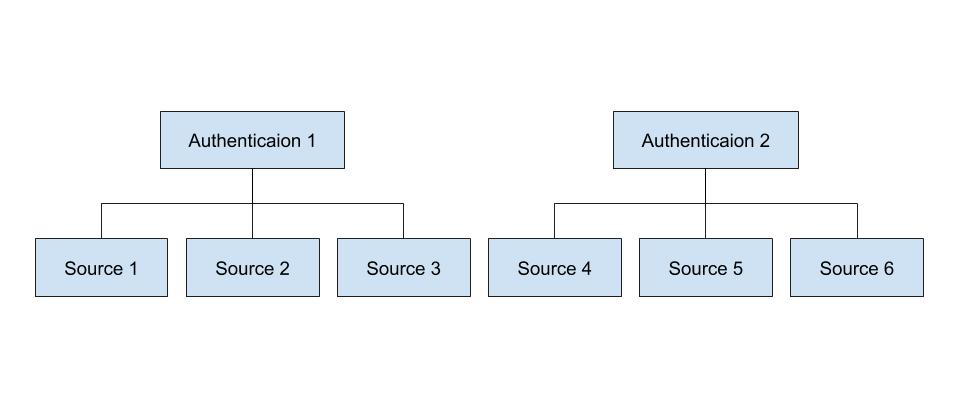
Authentication と呼ばれる資格情報(接続する際のユーザー名、パスワード、鍵情報など)設定を事前に行っておく必要があり、作成した Authentication を利用して、具体的なインポート設定を行うのが Source です。そのため Authenticaton と Source の関係は下図の通り 1対N になります。
以前は Authentication のことを Connection 、Source のことを Data Transfer と呼んでいました。
Source はスケジュール設定し、定期的に実行させることができるため、他の処理との依存関係を設ける必要がない場合は Source 単体で利用すると良いかと思います。
Workflowの td_load>: オペレータ
Data Connector によるインポート処理と他の処理(例えば Presto のクエリ)の間に依存関係を設けたい場合も多々あるかと思います。
Data Connector によるインポート処理の前に、既存のレコード達を別テーブルに退避させたいと言ったケースで考えてみましょう。実現するには Source のスケジュール設定では不十分で、退避が完了する前に Data Connector によるインポート処理が始まってしまうということが危惧されます。
そういったケースの場合、Workflow を利用することで簡単に依存関係を設けることができます。
Workflow から Data Connector の処理を実行するには td_load>: オペレータを利用します。
下記のように記載すると、データ退避処理が完了した後に Data Connector が実行されるため、並行して処理が実行されてしまうということを防ぐことができます。
### データ退避処理 +move_record: td>: data: "INSERT INTO tmp_table AS SELECT * FROM dest_table" ### Data Connector によるデータインポート処理 +import: td_load>: config.yml database: dest_db table: dest_table
そして td_load>: では下記2通りの使い方が存在します。
Authenticationを利用せず、資格情報もyamlファイルに記載する- 既存の
Sourceを利用する
前者の場合、Workflowの変数 ${...} を利用して動的に運用することが可能なことがメリットとして挙げられます。実装する際は treasure boxes にあるサンプルが役立つかもしれません。
インポート設定をyamlファイルとして作成し運用することは難しそうだという場合は、後者のほうがとっつきやすいかと思います。場合によって取捨選択していただくのが良いでしょう。
File Upload機能
本機能は手元にあるファイルをインポート対象とすることが可能で、TDコンソールから利用することができます。ファイルサイズに上限はありますが、アドホックにファイルをTDにアップロードしたい場合は有効かと思います。
定期的にインポートしなければならない、ファイルサイズが大きい場合は、後述する Embulk を利用する必要があります。

Bulk Import
Bulk Import とは、下記によって行われるインポート方法のことを指します。ローカル環境などに配置されているcsvファイルなどをインポートする際に利用するケースが多いかと思います。TDコンソールによるファイルアップロードはファイルサイズに上限が設けられているため、ファイルサイズが大きい場合は Bulk Import を利用する必要があるでしょう。
- Legacy Bulk Import(
td import:autoコマンド) - Embulk(embulk-output-tdプラグインによるTDへの書き出し)
Legacy Bulk Import(td import:auto)
LegacyなBulk Importは td import:auto コマンドにて利用することができます。このコマンドはCLI(Toolbelt)をインストールすると利用可能になるコマンドなのですが、注意点として数年開発を行っていない機能になるため、新たに利用する際はなるべく採用しないようにしていただくことを推奨しています。もちろん現在でも利用可能な機能ではありますが、それは以前から利用しているユーザーの処理に影響がないように後方互換性を保つためであって、新しい不具合などに対応することが基本的にはできません。
Embulk(embulk-output-tdプラグイン)
OSSである Embulk をインストールして実行することでTDにインポートすることが可能です。Legacy Bulk Importではなく現在はこちらを利用することをお勧めしています。
Embulk は本体以外にプラグインをインストールして利用することで多種多様なサービスと連携し、それらからインポート・エクスポートすることができることが特徴です。TDへインポートする場合はembulk-output-tdプラグインをインストールする必要があります。ドキュメントに手順なども記載されているのでよければ参照してみてください。
話は変わりますが、下記のように Data Connector のログに Embulk と表示されていることから、Embulk と Data Connector を混同してしまうかもしれませんが、実際はそれぞれ別々の機能となります。サポート問い合わせする際はどちらを利用しているのか意識していただくと認識の齟齬がなくなるため良いかと思います。
2020-11-24 03:45:24.041 +0000 [INFO] (main): td-client version: 0.7.41 2020-11-24 03:45:24.084 +0000 [INFO] (main): Logging initialized @485ms 2020-11-24 03:45:24.709 +0000 [INFO] (main): Started Embulk v0.10.19 ...
Query(Hive/Presto)
インポートと呼ぶと違和感がありますが、INSERT文やCREATE TABLE ... SELECT文(CTAS)を実行することでTDにデータを格納することが可能です。 既存のテーブルのデータを利用して別テーブルを生成したい場合にご利用いただくと良いかと思います。
注意点として、INSERT文を大量に実行するというユースケースはTDのアーキテクチャ上アンチパターンとなりお勧めできる方法ではありません。利用者側への影響として、Presto/Hiveそれぞれで同時に実行数に限りがあるため、INSERT処理でその枠を圧迫してしまい他の処理(SELECTも含め)が待たされてしまうなどが考えられます。そのため、特に少量のデータを頻繁に格納する必要がある場合は Streaming Import などを利用する方が良いでしょう。
最後に
インポートと一口に言っても、多種多様な方法が存在していることがわかったかと思います。それぞれ特性が異なるため、1つの方法に固執せず適切な方法を採用できると良いのではないかと思います。