こんにちは、Treasure Data(TD) サポートの伊藤です。
今回はクエリを扱う上で重要な要素であるデータ型について説明していきます。
データ型とは
そもそもデータ型とは何でしょう? 型システム入門 プログラミング言語と型の理論曰く、下記記載があります。
型システムとは、プログラムの各部分を、それが計算する値の種類に沿って分類することにより、プログラムがある種の振る舞いを起こさないことを保証する、計算量的に扱いやすい構文的手法である。
よくわからないという人は、データ型という制限を設けることで安全に処理を行うことができる、とイメージしていただくと良いでしょうか。例えば実際のデータが文字なのに、数値として処理をしてしまうと意図しない結果となってしまうことは容易に想像できるかと思います。そういった事態を防止するためにもデータ型という規則があり、利用者は必要に応じて適宜コントロールする必要があります。
TD以外のDB製品も利用している方はテーブルの各カラムにデータ型を設定する必要があるためふんわりと意識したことがあるかと思います。
TDを利用する際のデータ型の種類
スキーマレスであるTDにおいても、実際にデータを取り扱う上でデータ型は意識する必要があります。 まずTDにおけるデータ型は下記3種類あることをまずは理解しましょう。
- データを格納しているTDのデータ型(Plazma DB)
- クエリエンジンがHiveのときのデータ型
- クエリエンジンがPrestoのときのデータ型

TDでは同じデータ(Plazma DB)に対して、HiveとPrestoのどちらを利用してもアクセスすることができます。
データ型の観点で考えると、上図にある通り例えばクエリエンジンとしてPrestoを利用する場合はHiveは関係ないため、TDのデータ型とPrestoのデータ型を意識していただければと思います。
TDのデータ型
TDの場合、スキーマ・オン・リード方式でデータ型をメタデータ管理しているため、TDコンソール(ブラウザUI)上で各カラムのデータ型をシームレスに設定・変更することができます。文字列用のstring型に、数値用のint、long、fload、double型があると把握しておけばよいでしょう。
Hiveのデータ型
OSSのHiveのデータ型はドキュメントに記載されています。
特別詳細把握する必要はないかと思いますが、後述するデータ型を意識する必要があるケースの際に参考にしていただければと思います。
Prestoのデータ型
OSSのPrestoのデータ型はドキュメントに記載されています。
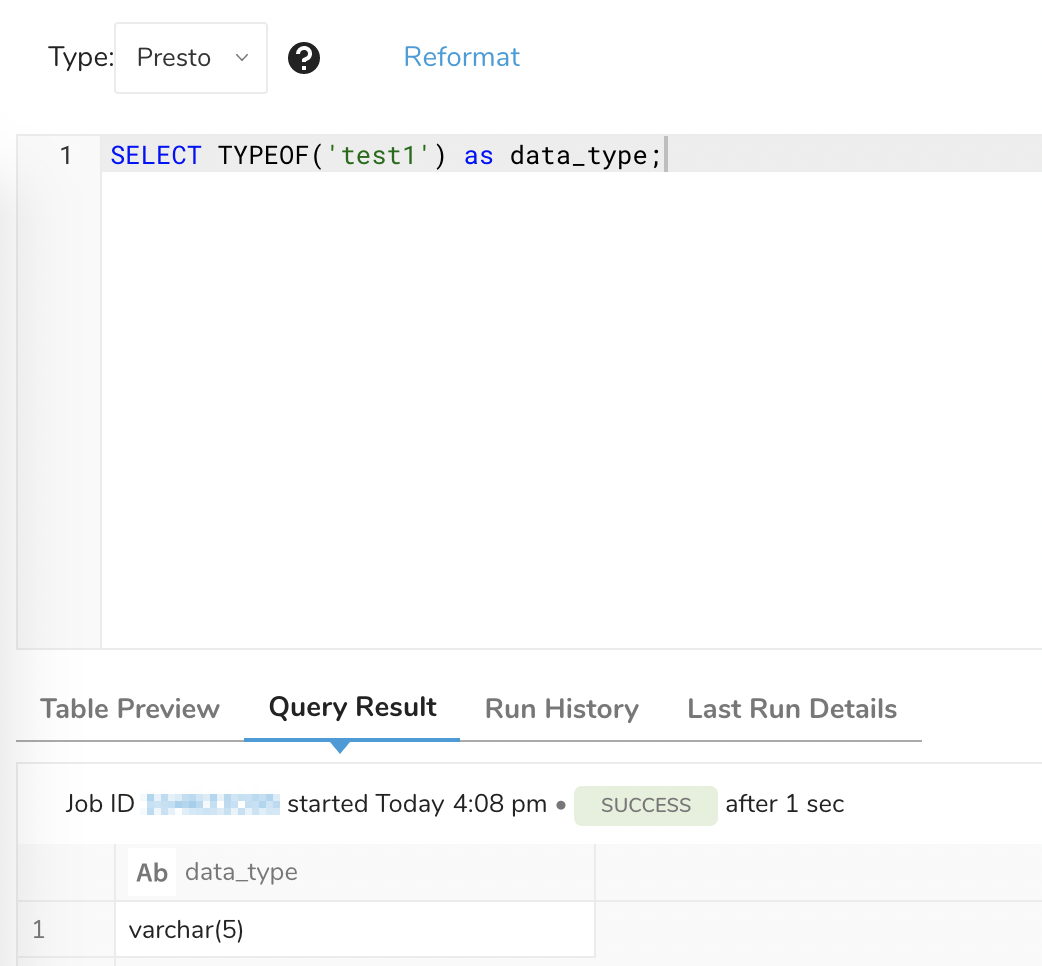
こちらも必要に応じて意識していただければと思いますが、Prestoの場合TYPEOF関数で対象データのデータ型を確認することが可能です。
SELECT TYPEOF('test1') as data_type;
各データ型の関係
TD、Hive、Prestoは全く別のコンポーネントになるため、最低限の互換性を意識する必要があります。具体的には、TDのドキュメントに記載されている対応表を見てみましょう(下記転記)。
| TD | Presto | Hive |
|---|---|---|
| int | bigint | smallint,int |
| long | bigint | bigint |
| double | double | decimal |
| float | double | float |
| double | double | double |
| Convert to string or int | boolean | boolean |
| string | varchar | string, varchar |
| string or Convert to long | date | string |
| string or Convert to long | timestamp | timestamp |
数値や文字列のデータ型の場合、特に意識しないでも問題ないケースがほとんどかと思います。
一方意識したほうが良いケースは例えば一番下の行で、TDのデータ型には残念ながらtimestamp型がありません。ですが、PrestoやHiveではtimestamp型が存在しており、timestamp型として取り扱わなければいけない・取り扱いたいケースが多々あります。その場合、データ格納先はTDになりますのでstring型としてデータを保持しておき、クエリで利用するときにデータ型を変換するという対応が必要です(詳細後述します)。
データ型を意識する必要があるケース
クエリで参照(SELECT文)するとき
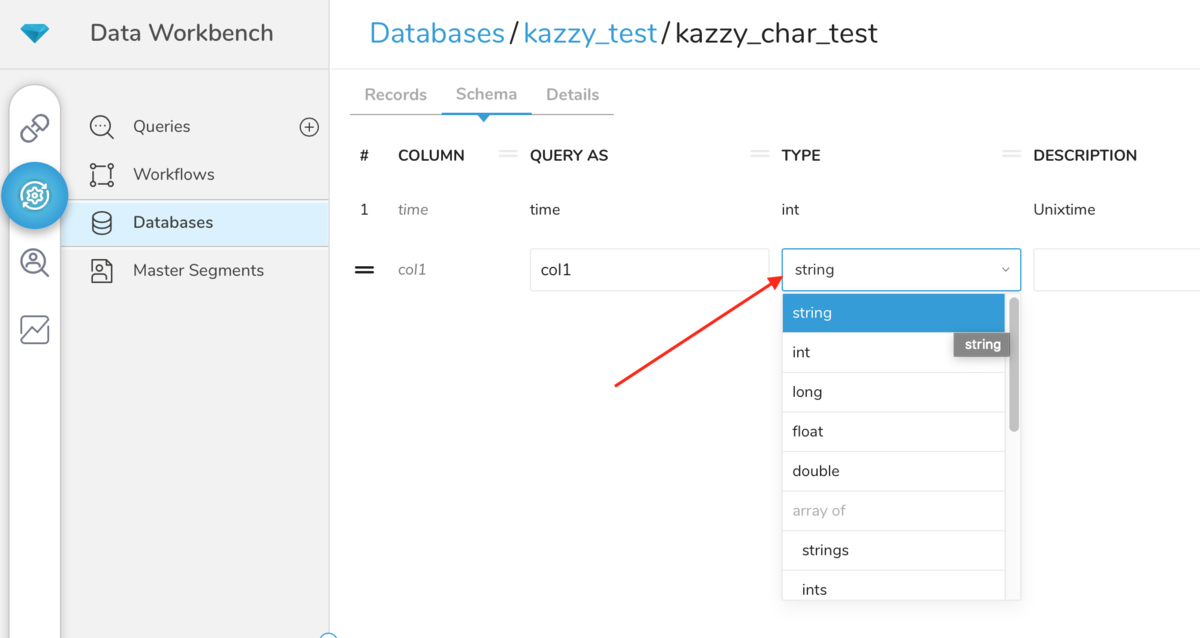
実際にTDに格納されているデータが文字列であろうが数字であろうが、ユーザーは任意のデータ型をカラムに設定することができます。通常のDB製品であれば格納されているデータに対応したデータ型である必要があるため、これはTDのメリットとしてよく挙げられます。ただし、注意が必要なケースがあります。もし格納されているデータが文字列の場合にデータ型が数値(int型など)の場合は、格納されているデータと一致しないためSELECT結果はNULLになります。
実際に検証してみましょう。まずは下記Prestoのクエリを実行します。作成された test_number テーブルの col1 カラムはstring型になり test1 という文字列が格納されます。SELECT文で確認するともちろん test1 というデータを参照できます。
CREATE TABLE test_number AS SELECT 'test1' AS col1 ;
では次にTDコンソールでcol1カラムのデータ型をstring型からint型に変更します。

変更後下記クエリでデータを参照してみましょう。
SELECT col1 FROM test_number ;
格納したはずのtest1という文字列が返らずにNULLが返っています。もちろんTD側のデータ型をstring型に戻せばtest1が返ります。

データを格納するとき(クエリで)
例えばCREATE TABLE文を用いてデータを格納するケースを考えます。
下記Prestoクエリはtimestamp型として 2021-02-25 17:00:00 というデータをTDに格納しようとしますが、先述した通りTDにはtimestamp型は存在しません。
CREATE TABLE test_timestamp AS SELECT timestamp '2021-02-25 17:00:00' AS col1 ;
そのため実際に実行してみると下記メッセージが出力されて失敗してしまいます。メッセージの意味は、カラムのタイプ(型)として timestamp はサポートされていないとなっていて想定通りですね。
Query 20210225_xxxxxx_xxxxx_xxxxx failed: Column type: timestamp not supported
回避策としては、下記のようにCAST関数を使ってtimestamp型からvarchar型に変換してあげることが挙げられます。
CREATE TABLE test_timestamp AS SELECT CAST(timestamp '2021-02-25 17:00:00' AS VARCHAR) AS col1;
注意点として、col1カラムは単純な文字列のカラムと区別がつかないため、参照するときには明示的に逆方向にデータ型を変換する必要があります。
SELECT CAST(col1 AS TIMESTAMP) AS col1 FROM test_timestamp;
関数を利用するとき
もともとのデータを全て必要な形で用意することは難しいので、クエリでデータを加工・集計して業務に必要なデータを抽出していると思います。クエリ(Hive、Presto)にはDB製品などと同様に便利な関数がたくさん用意されていますが、関数を利用する上でデータ型に注意を払う必要があります。
UPPER関数を例に説明します。
upper(string) → varchar
Converts string to uppercase.
注目するポイントは2点あります。
1つ目は引数(括弧の中)です。stringと記載されているので、その名の通り引数は文字列(数値などではなく)のデータ型である必要があります。
2つ目は返り値(結果)です。矢印の先が varchar となっているのでUPPER関数を適用した結果はvarchar型となります。
UPPER関数は引数で与えられた文字列を全て大文字で返す関数なので、インプットとなる引数は文字列のデータ型である制約を設けていると考えると良いかもしれません。また、大文字にした結果を返すので、関数適用後のデータ型が文字列であるvarchar型であるのもイメージしやすいかと思います。
実際に動作確認してみましょう。正しくUPPER関数を利用する下記クエリは、結果として ABC を返します。
SELECT UPPER('abc') AS col1 ;
ですが、下記のように数値を引数として実行してみると Unexpected parameters (integer) for function upper. Expected: upper(char(x)) , upper(varchar(x)) というエラーで失敗します。
SELECT UPPER(123) AS col1 ;
このように関数を利用する際には引数と返り値のデータ型を考慮する必要があります。 エラーとならない場合は意識する必要はありませんが、先述したようなエラーが発生した際はデータ型を確認してみてください。
NULLを格納するとき
テーブルを作成する際の初期データとして NULL を入れておきたいケースがあるかと思います。
NULL以外の場合と同じようなクエリを考えると下記のようになるかと思いますが、failed: line 1:1: Column type is unknown: col1 というエラーで失敗してしまいます。
CREATE TABLE test_null AS SELECT null AS col1 ;
これはエラーメッセージ通りではあるのですが、NULL はデータ型が文字列なのか数値なのかもわからないことに起因しています。
そのため、将来同じカラム(上記例ではcol1)に入ってくるデータと同じデータ型に変換してエラー回避してください。下記クエリであればエラーになりません。
CREATE TABLE test_null AS SELECT CAST(null AS VARCHAR) AS col1 ;
最後に
TDはHiveとPrestoという2種類のクエリエンジンを利用できるメリットがある一方で、TD(Plazma DB)を含めた各コンポーネントでのデータ型を考える必要があります。その際本記事が理解の助けとなると幸いです。
データ型という観点ではData Connectorでのインポート時の設定におけるデータ型もあるので、そちらに関しては別の記事で紹介したいと思います。