こんにちは、Treasure Dataサポートの伊藤です。
本日はData Tanks について説明していこうと思います。 本記事はよくあるお問い合わせに対する説明をする前段階として概要など説明していきます。
Data Tanks とは?
Data Tanks とは、オープンソースのRDBMSであるPostgreSQLをベースとしているサービスです。
Data Tanksは、Plazma DBと呼ばれるPrestoやHiveで参照できるデータベースと独立しています。そのため、Plazma DBに格納されているデータをData Tanksで利用するにはData Tanksへエクスポートする必要が、Data Tanksに格納されているデータをPrestoやHiveで利用するには逆にインポートする必要があります。
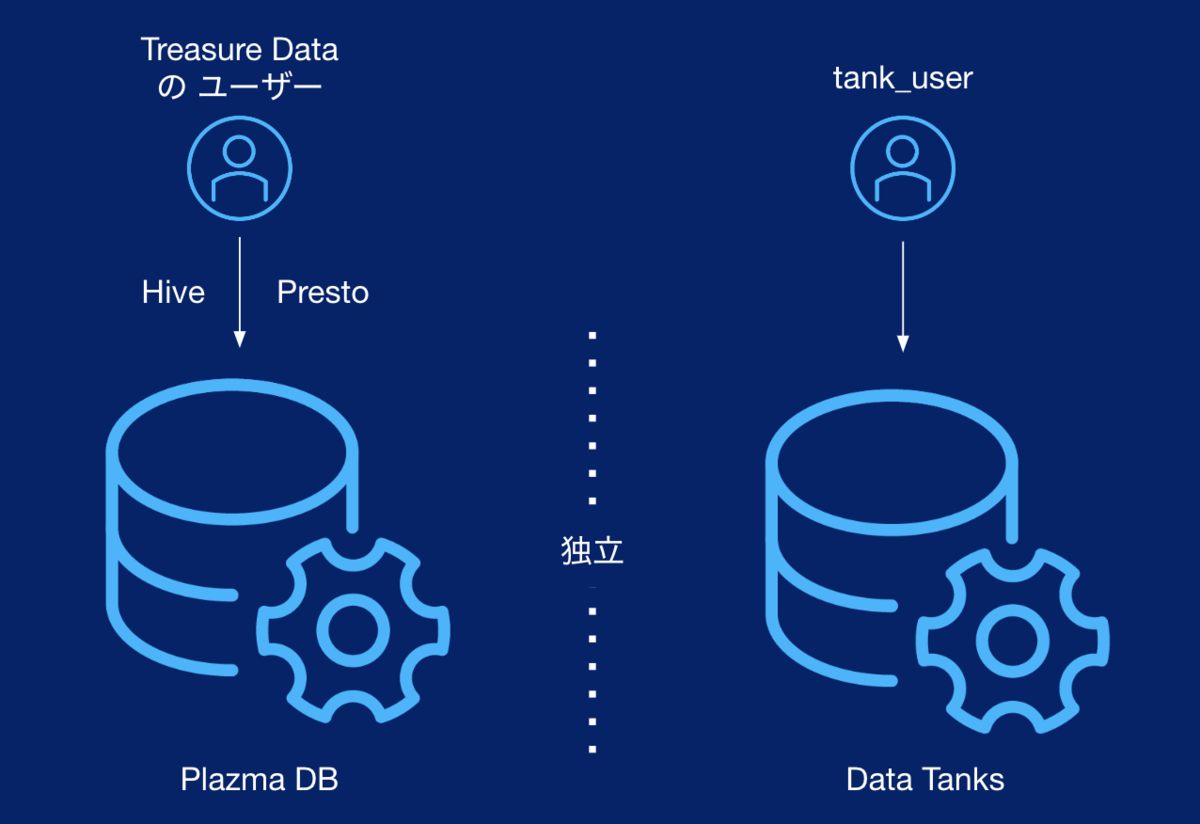
PrestoやHiveは分散処理システムであるため大規模データを取り扱うことが得意なのですが、一方で大量のデータから数行のみ参照するといったことは苦手です。
それとは対照的にData Tanksはインデックスを作成することで数行のレコードを参照するといったことが得意です。また、Presto/Hiveはシステム特性上同時実行数が少なく抑えられていることが多い(ご契約内容に依存)のですが、Data Tanksは同時接続数として100が設定されており、サードパーティ製のツールから同時にアクセスするといった際に採用を検討いただくと良いでしょう。
ただし、同じリソース(テーブルやレコードなど)を同時に複数人が使うことが想定されていることから、データの整合性を保つための仕組みとしてロックと呼ばれる排他制御方式が採用されており、Plazma DBと仕組みや特性が異なることは頭の片隅に置いておくと良いでしょう。
蛇足ではありますが、デフォルトでは有効化されていないPrestoからData Tanksへ接続する機能はあるのですが、Prestoの同時実行数上限の影響を受けてしまうのでなるべく分けて運用できるようにしていただくと良いでしょう。
Data Tanks の使い方
接続先のホスト名は?
ご契約ごとに接続先として固定されているIPアドレスが存在し、Data Tanks構築時に管理者へお渡ししています。
ユーザー名とパスワードは?
Data Tanksのユーザーは2ユーザーが用意されていますが、利用者が用いるユーザー名は基本的に tank_user となります。
tank_integration_user というユーザーも用意されていますが、こちらは後述するData TanksからインポートしたりData Tanksへエクスポートする際に利用されます。
どちらもパスワードは構築時にお渡ししているので、管理者へ確認していただくと良いでしょう。
接続制限はできるの?
Data Tanks は接続元のIPアドレスをホワイトリストとして登録することで、アクセス元が想定外となる場合は接続できないようにしています。 追加が必要な場合は担当のCustomer Successかサポートへご依頼ください。その際依頼者はTreasure Dataのユーザーの種類が Administrator もしくは Ownerである必要がありますので、留意すると依頼から作業までスムーズです。
Data Connector(Bulk Load)でData Tanksからインポートする
Data Tanksに格納されているレコードをPlazma DB(Presto/Hiveでアクセス可能なレコード)へインポートするにはPostgreSQL Import Integrationをお使いください。
datatank という名前のAuthenticationが用意されているので、そちらを用いてSourceを作成すると良いでしょう。
また、Workflowの td_load>: オペレータを用いる場合、下記のようなyamlファイルを用意し指定することでインポートできます。ご参考までに。
in: type: postgresql host: <Data TanksのIPアドレス> port: 5432 user: tank_integration_user password: ${secret:datatank_password} schema: public database: datatank query: "SELECT col1, col2 FROM test_table" filters: - type: add_time to_column: name: time type: timestamp from_value: mode: upload_time
Result ExportでData Tanksへエクスポートする
逆にPlazma DB(Presto/Hiveからアクセス可能)に格納されているレコードをData Tanksへエクスポートするには PostgreSQL Export Integrationをお使いください。
PrestoもしくはHiveにてクエリを用いて抽出した結果をData Tanksへエクスポートすることができます。 Workflowで実装する場合は下記のようになるでしょう。
_export: td: database: test_database +export_data_tank: td>: queries/example.sql result_connection: datatank result_settings: database: datatank table: test_table mode: replace
直接接続する
Data Tanksは先述した通りPostgreSQLベースのサービスとなっているため、psqlコマンドやpgAdminツールなどでアクセスすることが可能です。psqlコマンドで接続する場合は下記のようになるでしょう。
$ psql -h <Data TanksのIPアドレス> -p 5432 -d datatank -U tank_user
もちろんBIツールなどでPostgreSQLへの接続機能が提供されている場合はそちらで接続できることが期待されます。
傾向を把握するにはどうすればいいの?
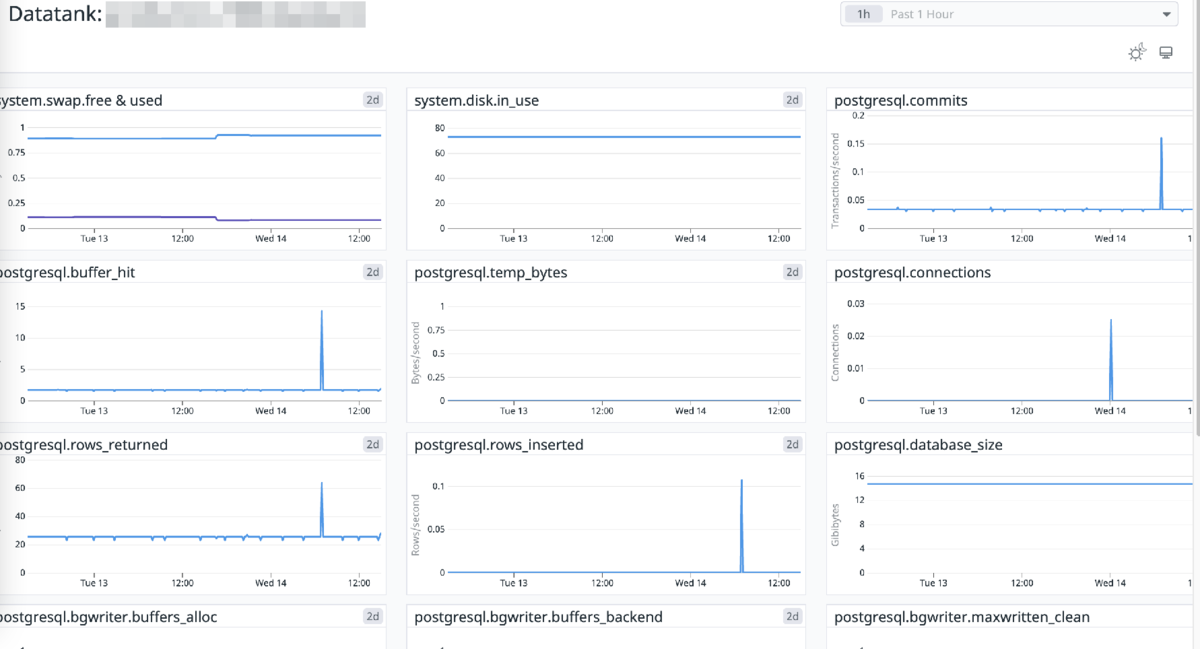
Data Tanksをご契約いただくと環境構築完了後対象のData Tanksの傾向を把握することができるダッシュボードのリンクを管理者へお渡ししています。
様々なグラフがダッシュボードに表示されているかと思いますが、例えば system.disk.in_use というグラフはディスク使用率(%)を表示しています。Plazma DBとは異なり利用できるディスク領域のサイズ上限がありますので、新たにデータ連携を始めるなどを想定している場合は事前にこちらで傾向を確認するようにしておくと良いでしょう。
最後に
いかがでしたでしょうか? 今回は Data Tanks を利用する上で最低限必要だったり気にするであろうポイントについて説明してみました。 読んでいただいた方は感じたかと思いますが、各種Treasure Dataへ依頼する必要があったり、設定の柔軟性もあまりないという特徴があります。それらを改善した Data Tanks v2と呼ばれるサービスも提供予定ですので、興味がある方はご連絡ください!
次回は Data Tanks を利用している時に遭遇するトラブルについて説明する予定です。どうぞお楽しみに!